July 2016
A picture is worth a thousand words
Or how to make word clouds with Python
This post shows a simple example of how to build word clouds from your
favorite text. It uses the Python library
The source text
For the source text I picked "The Possessed", a novel by Russian writer Fyodor
Dostoyevsky, one of my favorite auhors. I got the full text from
Project Gutenberg, a
great resource for free books. By the way, I think Project Gutenberg provides a
great service to the community and I would very much encourage you to support them.
I downloaded the plain text (UTF-8) version of the book using
wget http://www.gutenberg.org/ebooks/8117.txt.utf-8 -O ThePossessed.txt
A wrapper function to word_cloud
I wrote a simple wrapper function called
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
def make_word_cloud(input_text, mask, output_file_name, stopwords=None, extra_stopwords=None,
bckgrd_color = "white", max_words=2000):
"""Generate a word cloud and write it to .png file.
Keyword arguments:
input_text -- path to plain text file
mask -- path to mask image
output_file_name -- string name to output .png file
stopwords -- list of stop word strings (default None)
extra_stopwords -- list of extra stop word strings (default None)
bckgrd_color -- background color (default "white")
max_words -- maximum number of words (default 2000)
"""
# Read the whole text
text = open(input_text).read()
# Load the mask image
mask = np.array(Image.open(mask))
# Load stop word list
stopwords = set(stopwords)
# Add extra stop words if provided
if extra_stopwords is not None:
[stopwords.add(word) for word in extra_stopwords]
# Call WordCloud
wc = WordCloud(background_color=bckgrd_color, max_words=max_words,
mask=mask, stopwords=stopwords)
# Generate word cloud
wc.generate(text)
# Write to file
wc.to_file(output_file_name)
Generating a word cloud
This is all we need to make our word cloud. We can call the wrapper function
and use the list of stop words provided by
make_word_cloud(input_text="ThePossessed.txt", mask="devil_stencil.jpg",
output_file_name="ThePossessed.png", stopwords=STOPWORDS)
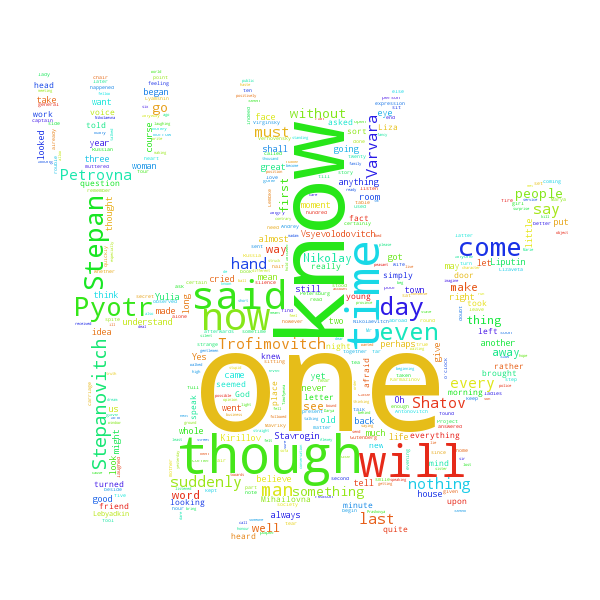
Looking at the output image, the result is a nicely balanced word cloud with cool colors and making up the shape we chose. The cloud is rather disapointing when it comes to the informative power, though. We can see some character names and a few interesting words, but the most important words are still quite generic and uninformative.
A better stop word collection
The obvious next step is to get a better stop word collection. One of the most popular NLP open source Python libraries is the Natural Language Toolkit (NLTK). So let's try their stop word collection.
from nltk.corpus import stopwords
nltk_sw = stopwords.words('english')
make_word_cloud(input_text="ThePossessed.txt", mask="devil_stencil.jpg",
output_file_name="ThePossessed_nltk_sw.png", stopwords=nltk_sw)
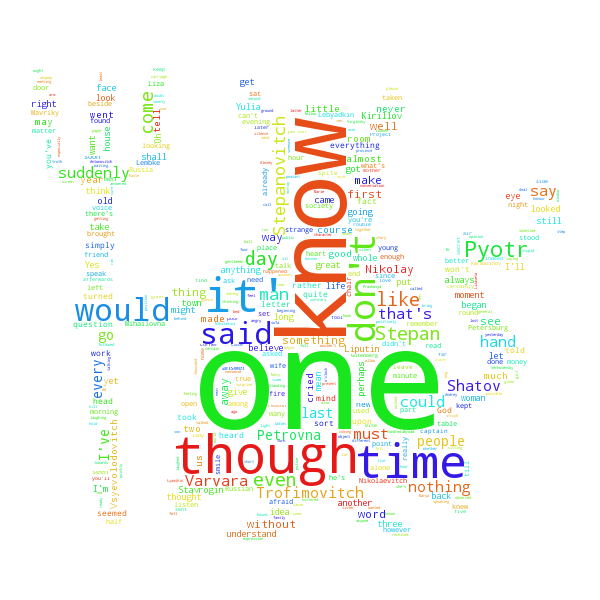
No improvement here. The result looks really similar and it is still dominated by
common, uninformative words. As you can see here below, both the
print len(STOPWORDS)
# 183
print len(nltk_sw)
# 153
A little googling around reveals a more extensive stop word list compiled by the IR Multilingual Resources at UniNE (University of Neuchâtel, Switzerland). Their English stop word list includes 571 words, so it looks like a good bet.
wget http://members.unine.ch/jacques.savoy/clef/englishST.txt
Since we downloaded this list as a text file it will require a little more work to get into Python. This little function will do the trick.
def load_words_from_file(path_to_file):
"""Read text file return list of words."""
sw_list = []
with open(path_to_file, 'r') as f:
[sw_list.append(word) for line in f for word in line.split()]
return sw_list
And now we are ready to give this longer list a try. Let's see how well it works.
# Load stop words
UniNE_sw = load_words_from_file('englishST.txt')
make_word_cloud(input_text="ThePossessed.txt", mask="devil_stencil.jpg",
output_file_name="ThePossessed_UniNE.png", stopwords=UniNE_sw)
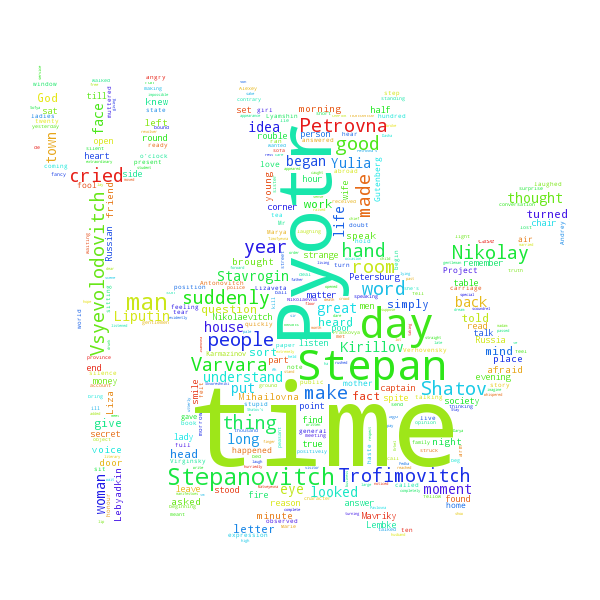
Much better. We got rid of most common and uninformative words and managed
to get a pretty interesting word cloud. And thanks to the
Happy "word clouding"!